实验一主要涉及调用系统调用函数,这些系统调用函数基本都是符合POSIX规范的,和操作系统本身关系较小,在调试的时候也可以先把程序在外部的Linux下跑通然后再放进xv6中运行。
基本没什么特别的内容,按说明的做就行了。
#include "kernel/types.h"
#include "user/user.h"
int main(int argc, char *argv[]) {
int i;
if (argc < 2) {
printf("sleep: tick number is not specified\n");
exit(0);
}
i = atoi(argv[1]);
if (i <= 0) {
printf("sleep: tick number is invalid\n");
exit(0);
}
sleep(i);
exit(0);
}涉及进程创建和管道,当一个进程在read的时候会挂起直至读到内容,所以进程的执行顺序也是非常清晰的。
#include "kernel/types.h"
#include "user/user.h"
int main() {
int parent_fd[2], child_fd[2];
char buf[16];
pipe(parent_fd); pipe(child_fd);
if (fork() == 0) {
read(parent_fd[0], buf, 4);
buf[4] = '\0'; printf("%d: received %s\n", getpid(), buf);
write(child_fd[1], "pong", 4);
} else {
write(parent_fd[1], "ping", 4);
read(child_fd[0], buf, 4);
buf[4] = '\0'; printf("%d: received %s\n", getpid(), buf);
}
exit(0);
}这个算是管道比较高级的应用,有点流水线那味道。根据实验文档所给的参考链接里的图片
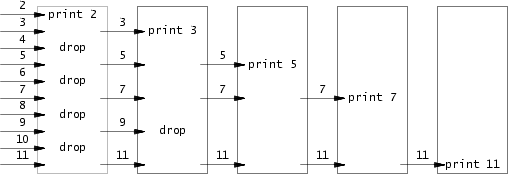
给人一种每个进程都是筛完合数然后将筛完的数一股脑传给下一级进程的感觉,其实不然,这样一方面需要多一个缓冲区来存储筛完的数,另一方面也不方便并行。实际上应该更好地利用管道的队列性质。对于每个进程,从输入管道得到第一个质数后就创建子进程,然后对输入管道剩下的数进行筛选,如果合法就放入输出管道,这样多个进程同时操作,也不用缓冲区了。子进程中创建子进程这种操作很难直接表示,需要用到递归思想。
#include "kernel/types.h"
#include "user/user.h"
void f(int pp) {
int prime;
if (read(pp, (char *)&prime, 4) != 0) {
printf("prime %d\n", prime);
int p[2]; pipe(p);
if (fork() == 0) {
close(p[1]); f(p[0]);
} else {
int t;
while (read(pp, (char *)&t, 4) != 0) {
if (t % prime != 0) write(p[1], (char *)&t, 4);
}
close(p[1]); close(p[0]); close(pp); wait(0);
}
} else close(pp);
}
int main() {
int i, p[2]; pipe(p);
if (fork() == 0) {
close(p[1]); f(p[0]);
} else {
for (i = 2; i < 36; i++) write(p[1], (char *)&i, 4);
close(p[1]); close(p[0]); wait(0);
}
exit(0);
} 注意每次fork以后会给当前的管道添加一个引用,而想要关闭一个管道必须将它的所有引用都关闭才行。因此每次在fork之后关闭不用的管道是一个好习惯,防止忘关导致其他进程读不到eof。
基本上套用ls.c里的内容。
#include "kernel/types.h"
#include "kernel/stat.h"
#include "user/user.h"
#include "kernel/fs.h"
const char *now = ".", *par = "..";
char* fmtname(char *path) {
char *p;
for(p = path + strlen(path); p >= path && *p != '/'; p--);
p++;
return p;
}
void find(char *path, char *pattern) {
char buf[128], *p;
int fd;
struct dirent de;
struct stat st;
if((fd = open(path, 0)) < 0){
printf("find: cannot open %s\n", path);
return;
}
if(fstat(fd, &st) < 0){
printf("find: cannot stat %s\n", path);
close(fd);
return;
}
switch(st.type){
case T_FILE:
if (strcmp(pattern, fmtname(path)) == 0) printf("%s\n", path);
break;
case T_DIR:
if(strlen(path) + 1 + DIRSIZ + 1 > sizeof buf){
printf("ls: path too long\n");
break;
}
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
while(read(fd, &de, sizeof(de)) == sizeof(de)){
if(de.inum == 0) continue;
if (strcmp(de.name, now) == 0 || strcmp(de.name, par) == 0) continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
find(buf, pattern);
}
break;
}
close(fd);
}
int main(int argc, char *argv[]) {
if (argc < 3) {
printf("find: argument is less than 2\n");
exit(0);
}
find(argv[1], argv[2]); exit(0);
}也没啥好说的,基本就是对命令行参数和标准输入的字符串处理。
#include "kernel/types.h"
#include "kernel/param.h"
#include "user/user.h"
int main(int argc, char *argv[]) {
char line[256], *p[MAXARG], ch;
int lines = 0, linen, ps = 0, pn, i, j;
for (i = 0; i < argc - 1; i++) {
p[ps++] = line + lines;
for (j = 0; j < strlen(argv[i + 1]); j++)
line[lines++] = argv[i + 1][j];
line[lines++] = '\0';
}
linen = lines; pn = ps; p[pn++] = line + linen;
while (read(0, &ch, 1) > 0) {
if (ch == '\n') {
line[linen++] = '\0'; p[pn++] = 0;
if (fork() == 0) exec(argv[1], p);
else {
wait(0); linen = lines; pn = ps; p[pn++] = line + linen;
}
} else if (ch == ' ') {
line[linen++] = '\0'; p[pn++] = line + linen;
} else line[linen++] = ch;
}
exit(0);
}