
最近向老师借了一块Ultra96 V2开发板学习FPGA。之前虽然也有接触过FPGA开发板,但第一次用的是只有一个FPGA核的Artix-7开发板,用的也是最传统的流程,即写好verilog模块,调一下网表文件,然后直接烧录到FPGA中;第二次用的是Zynq系的Pynq z2开发板了,但是也是用别人生成好的比特流文件。所以这是我第一次使用Zynq系的开发板编写硬件程序。这里记录一个简单的HLS程序从编写到生成再到板子上运行的过程。
比较简单,从这里下载对应的镜像,然后烧录到SD卡上。烧录的过程不一定要使用教程里推荐的软件,我就直接用平常制作系统盘的refus程序,经测试也可以。卡插上,连接Micro USB和电源就可以启动开发板。这个Micro USB可以充当网线的功能,所以开发板启动完可以在浏览器中输入192.168.3.1使用板子的Jupyter Notebook服务器,也可以直接ssh连接xilinx@192.168.3.1。
HLS(High Level Synthesis,高层次综合)是Xilinx搞的将C/C++语言转换成Verilog/VHDL的技术,本文用HLS实现硬件程序。首先打开HLS IDE,创建项目,其中选择硬件的部分我选的是xqzu3eg-sfrc784-1-i。创建结束后添加代码(计算两个数的积):
#include "product.h"
void product(in_t a, in_t b, out_t &c) {
#pragma HLS INTERFACE s_axilite port=c
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE ap_ctrl_none port=return
c = a * b;
}product.h包含了in_t和out_t的定义,这两个都是int类型。中间四行是给端口添加的修饰,前三行指定a、b和c为通过AXI总线控制的寄存器,在ZYNQ系的开发板中,PS端需要通过AXI总线读写寄存器来控制PL端的输入输出;第四行表示不生成product函数的返回值端口。注意用HLS编写的模块不能把模块输出作为函数的返回值,因为编译后如果生成返回值端口,在硬件模块正常运行的情况下返回值端口总是为0,我就被坑过一次,模块输出应该作为可变参数返回。
这里我省略test bench的编写和C仿真的过程,直接点C Synthesis综合C代码,综合结束后点Export RTL生成IP核,后面在Vivado中使用。
打开Vivado,创建项目,硬件的部分选择和HLS IDE里选的一样。创建结束后,在窗口左侧的Flow Navigator里点IP Catalog。在打开的IP Catalog标签里右键Vivado Repository,点Add Repository。这时可以选择刚才在HLS IDE里生成的IP核所在文件夹,一般是HLS项目文件夹/solution1/impl/ip,选择后在Vivado Repository上方就可以看到User Repository了,递归点开下拉箭头可以看到名为Product的IP核。
接下来开始连接IP,在窗口左侧的Flow Navigator点Create Block Design。在中间的Diagram选项卡里右键空白处,点Add IP。在弹出的选择框里搜zynq,然后创建Zynq Ultra+ MPSoC,按此步骤再添加刚才自己创建的IP核Product(搜hls),这时上面会弹出一个Run Connection Automation的提示,点它再确认对话框,系统就会自动生成相应的连线:
接着保存Block Design。点左侧的Generate Block Design生成各IP的组合,再点左侧的PROJECT MANAGER回到项目视图,在中间的Sources窗口右键刚才创建的Block Design文件(扩展名为bd),点Create HDL Wrapper生成IP组合模块的verilog文件。接着点左侧的Generate Bitstream生成比特流,如果提示还没Implementation就按提示先Implementation。
接下来就是在板子上运行了。刚才编写的硬件程序是在PL端运行的,还需要PS端的软件程序启动和控制硬件程序。正常的开发流程是使用Vitis IDE编写C/C++程序,然后利用串口通信将比特流烧录到PL端,再将软件程序传输到存储卡中。不过UltraV2开发板支持PYNQ框架,这个框架能让用户使用Python方便地编写软件程序,还能直接启动存储卡上的比特流文件,不需要串口通信。所以这里介绍基于PYNQ的方法。
首先将比特流文件和属性文件传到存储卡中,这一步可以用浏览器打开Jupyter Notebook页面上传,也可以用scp命令。比特流文件的路径一般是Vivado项目文件夹/项目名.runs/impl_1/BlockDesign名_wrapper.bit,属性文件的路径一般是Vivado项目文件夹/项目名.srcs/sources_1/bd/BlockDesign名/hw_handoff/BlockDesign名.hwh,两者需传到存储卡同个路径下,名字(不包括扩展名)也要改成一样,不然PYNQ无法识别。注意这个属性文件在老版本的PYNQ中需要的是tcl文件,新版本(本文使用的PYNQ版本为2.7.0)换成了hwh文件,所以可能比较老的教程和本文不同。
然后开始写Python脚本:
from pynq import Overlay
# 读取比特流文件,假设其放在用户目录
overlay = Overlay('/home/xilinx/design_1_wrapper.bit')
# product_0是Block Design中用户定义的IP核的名字,见上图IP核上方黑色标题
product = overlay.product_0
# 利用AXI总线的功能,写入模块的输入端口寄存器
product.register_map.a = 8
product.register_map.b = 8
# 利用AXI总线的功能,打印模块的输出端口寄存器的值
print(product.register_map.c)输出为64,符合预期。
可以输出product.register_map查看模块包含的寄存器,除了a、b和c还有一些控制寄存器。除了通过以上的方式读写寄存器,还可以通过地址的方式,查看HLS项目文件夹/solution1/impl/ip/drivers/模块名_v版本号/src/x模块名_hw.h:
// ==============================================================
// Vivado(TM) HLS - High-Level Synthesis from C, C++ and SystemC v2019.2 (64-bit)
// Copyright 1986-2019 Xilinx, Inc. All Rights Reserved.
// ==============================================================
// AXILiteS
// 0x00 : reserved
// 0x04 : reserved
// 0x08 : reserved
// 0x0c : reserved
// 0x10 : Data signal of a
// bit 31~0 - a[31:0] (Read/Write)
// 0x14 : reserved
// 0x18 : Data signal of b
// bit 31~0 - b[31:0] (Read/Write)
// 0x1c : reserved
// 0x20 : Data signal of c
// bit 31~0 - c[31:0] (Read)
// 0x24 : Control signal of c
// bit 0 - c_ap_vld (Read/COR)
// others - reserved
// (SC = Self Clear, COR = Clear on Read, TOW = Toggle on Write, COH = Clear on Handshake)
#define XPRODUCT_AXILITES_ADDR_A_DATA 0x10
#define XPRODUCT_AXILITES_BITS_A_DATA 32
#define XPRODUCT_AXILITES_ADDR_B_DATA 0x18
#define XPRODUCT_AXILITES_BITS_B_DATA 32
#define XPRODUCT_AXILITES_ADDR_C_DATA 0x20
#define XPRODUCT_AXILITES_BITS_C_DATA 32
#define XPRODUCT_AXILITES_ADDR_C_CTRL 0x24里面给出了寄存器的映射方案,因此上面的Python代码后几行我们也可以这样写:
有时我们需要将数组(的头指针)传给模块,由模块对数组的所有元素进行计算。这种情况下HLS会生成BRAM端口的硬件模块,将参与计算的值存在BRAM中,模块再从BRAM中取数。这里给出一个计算向量点积的HLS代码:
#include "product.h"
void product(in_t a[VSIZE], in_t b[VSIZE], out_t &c) {
#pragma HLS INTERFACE s_axilite port=c
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE ap_ctrl_none port=return
out_t r = 0;
for (int i = 0; i < VSIZE; i++) r += a[i] * b[i];
c = r;
}VSIZE常量在product.h里定义了是16,其他和简单端口的HLS程序一样。按照前面的步骤生成IP核、创建Block Design并生成比特流。新的IP核和原来的端口一致,所以连线也没有变化。将比特流和属性文件放入存储卡,然后写Python脚本:
from pynq import Overlay
import numpy as np
overlay = Overlay('/home/xilinx/design_1_wrapper.bit')
product = overlay.product_0
# 用numpy创建第一个向量数组,值为[ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15]
a = np.array(range(16), dtype=np.int32)
# 用numpy创建第二个向量数组,值为[32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47]
b = np.array(range(32, 48), dtype=np.int32)
# 将数组a写入第一个BRAM端口中
product.write(0x40, a.tobytes())
# 将数组b写入第二个BRAM端口中
product.write(0x80, b.tobytes())
print(product.register_map.c)结果为5080,符合预期。
可以看到AXI总线也支持通过地址读写BRAM,查看HLS项目文件夹/solution1/impl/ip/drivers/模块名_v版本号/src/x模块名_hw.h:
// ==============================================================
// Vivado(TM) HLS - High-Level Synthesis from C, C++ and SystemC v2019.2 (64-bit)
// Copyright 1986-2019 Xilinx, Inc. All Rights Reserved.
// ==============================================================
// AXILiteS
// 0x00 : reserved
// 0x04 : reserved
// 0x08 : reserved
// 0x0c : reserved
// 0xc0 : Data signal of c
// bit 31~0 - c[31:0] (Read)
// 0xc4 : Control signal of c
// bit 0 - c_ap_vld (Read/COR)
// others - reserved
// 0x40 ~
// 0x7f : Memory 'a' (16 * 32b)
// Word n : bit [31:0] - a[n]
// 0x80 ~
// 0xbf : Memory 'b' (16 * 32b)
// Word n : bit [31:0] - b[n]
// (SC = Self Clear, COR = Clear on Read, TOW = Toggle on Write, COH = Clear on Handshake)
#define XPRODUCT_AXILITES_ADDR_C_DATA 0xc0
#define XPRODUCT_AXILITES_BITS_C_DATA 32
#define XPRODUCT_AXILITES_ADDR_C_CTRL 0xc4
#define XPRODUCT_AXILITES_ADDR_A_BASE 0x40
#define XPRODUCT_AXILITES_ADDR_A_HIGH 0x7f
#define XPRODUCT_AXILITES_WIDTH_A 32
#define XPRODUCT_AXILITES_DEPTH_A 16
#define XPRODUCT_AXILITES_ADDR_B_BASE 0x80
#define XPRODUCT_AXILITES_ADDR_B_HIGH 0xbf
#define XPRODUCT_AXILITES_WIDTH_B 32
#define XPRODUCT_AXILITES_DEPTH_B 16可以看到a和b都有对应的base、high、width和depth常量,其中base表示BRAM在总线中映射的首地址,high表示末地址,width和depth则是BRAM的位宽和深度。write方法除了可以往地址里写数,还可以往地址里写字节串,所以用Numpy数组的tobytes方法将数组转换成字节串就可以写入BRAM中了。
BRAM是FPGA片上的存储器,速度快但是容量低,当用户需要从PS端往PL端传输大量数据时就力不从心了。解决方法是使用PS端和PL端共享的DRAM,也就是内存,把需要用到的大量数据传到内存中,再由硬件按需读取,这时模块的端口就是DRAM端口,硬件会将端口寄存器里的值解释为DRAM地址然后从DRAM中读数。
HLS代码如下:
#include "product.h"
void product(in_t a[VSIZE], in_t b[VSIZE], out_t &c) {
#pragma HLS INTERFACE m_axi depth=512 port=b
#pragma HLS INTERFACE m_axi depth=512 port=a
#pragma HLS INTERFACE s_axilite port=c
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE ap_ctrl_none port=return
out_t r = 0;
for (int i = 0; i < VSIZE; i++) r += a[i] * b[i];
c = r;
}和前面的代码基本一致,但多了两个端口修饰,将a和b同时声明为m_axi类型,表示这两个端口是DRAM端口,寄存器的值是DRAM地址,计算时要从DRAM中取数。depth是取数的位数,数组大小为16,int是32位,16乘32结果为512。
继续按照前面的步骤生成IP核、创建Block Design,这时会发现product核的右侧多了一个m_axi_gmem的端口,需要经过总线连到DRAM。首先需要给ZYNQ核添加DRAM端口,办法是双击Zynq核对IP进行定制,在对话框左侧选择PS-PL Configuration,右边依次展开PS-PL Interfaces、Slave Interfaces、AXI HP,勾选AXI HPC0 FPD,然后点OK。这时会发现ZYNQ核多了一个S_AXI_HPC0_FPD端口(和一个时钟端口),再点Run Connection Automation,就可以自动连接了:
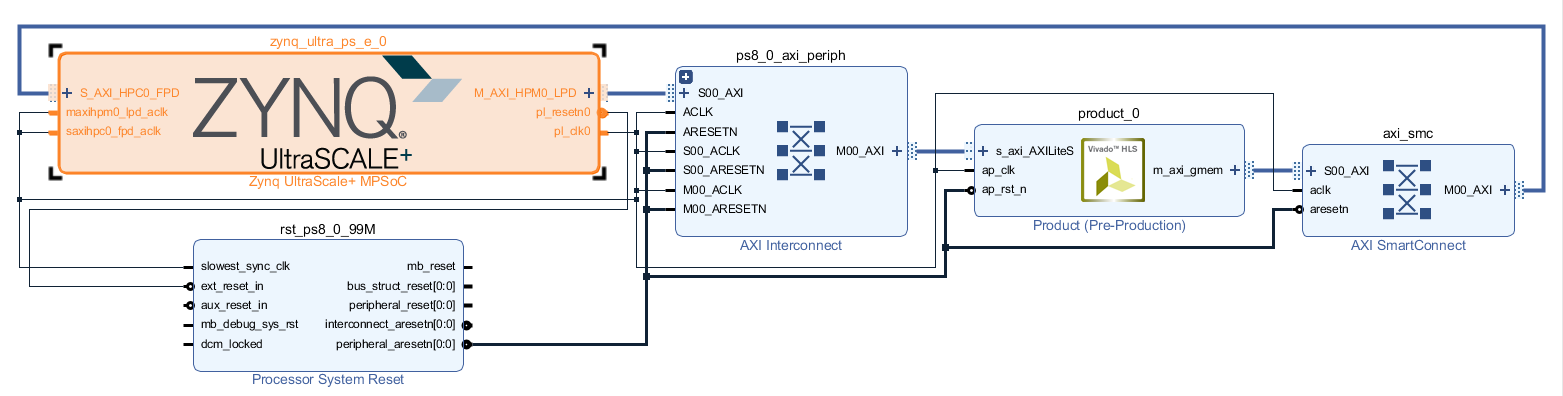
相比前面多了一个AXI SmartConnect将product核和Zynq多出来的总线端口相连。继续按前面的步骤一直到生成比特流并传输文件。用来控制的Python脚本:
from pynq import Overlay, allocate
import numpy as np
overlay = Overlay('/home/xilinx/design_1_wrapper.bit')
product = overlay.product_0
a = np.array(range(16), dtype=np.int32)
b = np.array(range(32, 48), dtype=np.int32)
# 创建连续的内存区域,供PL端读取
mem_a = allocate((16, ), dtype=np.int32)
mem_b = allocate((16, ), dtype=np.int32)
# 将numpy数组中的元素复制到刚才创建的内存区域中
np.copyto(mem_a, a)
np.copyto(mem_b, b)
# 获取刚才创建的内存区域的地址
addr_a = mem_a.device_address
addr_b = mem_b.device_address
# 将地址传给product的端口寄存器
product.register_map.a = addr_a
product.register_map.b = addr_b
print(product.register_map.c)结果为5080,符合预期。
注意Numpy直接创建的数组不一定是连续的内存区域,也很难获得物理地址,所以pynq提供了一个继承自Numpy数组的缓冲区类型,既能被PL端读取,又能很方便地和Numpy之间互相传数据。注意老版本分配缓冲区的做法是先实例化一个名为Xlnk的类,然后用这个类分配缓冲区,新版本(本文使用的PYNQ版本为2.7.0)修改了API。
目前网上关于这方面的教程良莠不齐,要么是只教到怎么装系统的,要么是用Vitis IDE走串口烧录的,要么只涉及简单端口的传输,要么针对的是常见的Zynq7000开发板,我也参考结合了很多资料才成功跑通并总结出本文,尤其是DRAM端口的相关内容。不过网上设计DRAM的一般使用的是流式传输,数据的传输是异步的,这种方法效率更高,适合传输大量数据,在Block Design的时候需要加上DMA核并连接中断相关端口,后面有时间再研究这种方法。
如果使用HDL语言编写硬件模块流程也应该类似,Vivado应该有往HDL模块自动加上AXI总线协议并打包成IP核的功能,这点我也未尝试,后面有时间再研究。